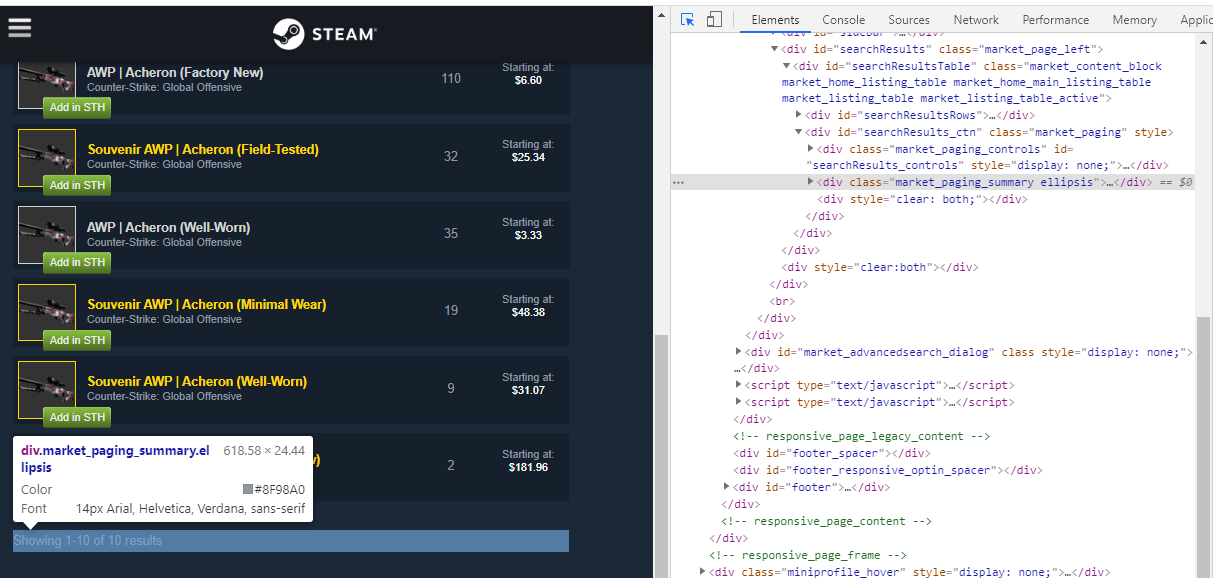
Решил доделать старый проэкт для сбора статистики Steam. Нуждаюсь в советах опытных форумчан.
Отрываю страницу с результатами поиска. Eсли страница результатов одна - вылетает с ошибкой превышения интервала ожидания 20 с
public static class WaitHelper
{
public static TResult WaitUntil<TResult>(IWebDriver webDriver,
TimeSpan timeout,
Func<IWebDriver, TResult> condition,
string message = "")
{
var wait = new WebDriverWait(webDriver, timeout);
if (!String.IsNullOrEmpty(message))
wait.Message = message;
return wait.Until(condition);
}
}
/// <summary>
/// Запуск браузера з потрібної сторінки
/// </summary>
private void btnStartBrowser_Click(object sender, EventArgs e)
{
try
{
// Відкрити потрібну сторінку
browser = new OpenQA.Selenium.Chrome.ChromeDriver();
browser.Navigate().GoToUrl(this.tbSteamInitialLink.Text);
WebDriverWait ww = new WebDriverWait(browser, TimeSpan.FromSeconds(20));
// шукати елементи-ідентифікатори
try
{
// 1 сторінка результатів
ww.Until(SeleniumExtras.WaitHelpers.ExpectedConditions.ElementIsVisible(By.ClassName("market_paging_summary ellipsis")));
}
catch
{
// Результатів більше 1 сторінки
ww.Until(SeleniumExtras.WaitHelpers.ExpectedConditions.ElementIsVisible( By.ClassName("market_paging_pagelink")));
List<IWebElement> Pages = browser.FindElements(By.ClassName("market_paging_pagelink")).ToList();
}
}
catch (Exception ex)
{
// Помилка браузера
browser.Close();
MessageBox.Show("Помилка відкриття браузера\n" + ex.Message,
"Ініціалізація браузера",
MessageBoxButtons.OK, MessageBoxIcon.Error);
}
}
Елемент с class=“market_paging_summary ellipsis” должен быть на странице и видимым, но не работает задум.
Как выше уже написали - это два класса. Нужно использовать поиск подстроки в КлассНейм, но не факт, что там не найдётся ещё строк с таким же содержанием.
А если разобраться - любой из этих поисков в своём нутре обращается всё к тому же поиску по XPath
CSS selectors perform far better than Xpath and it is well documented in Selenium community. Here are some reasons,
Xpath engines are different in each browser, hence make them inconsistent
IE does not have a native xpath engine, therefore selenium injects its own xpath engine for compatibility of its API. Hence we lose the advantage of using native browser features that WebDriver inherently promotes.
Xpath tend to become complex and hence make hard to read in my opinion
However there are some situations where, you need to use xpath, for example, searching for a parent element or searching element by its text (I wouldn’t recommend the later).
You can read blog from Simon here . He also recommends CSS over Xpath.
If you are testing content then do not use selectors that are dependent on the content of the elements. That will be a maintenance nightmare for every locale. Try talking with developers and use techniques that they used to externalize the text in the application, like dictionaries or resource bundles etc. Here is my blog that explains it in detail.
edit 1
Thanks to @parishodak, here is the link which provides the numbers proving that CSS performance is better
The debate between cssSelector vs XPath would remain as one of the most subjective debate in the Selenium Community. What we already know so far can be summarized as:
People in favor of cssSelector say that it is more readable and faster (especially when running against Internet Explorer).
While those in favor of XPath tout it’s ability to transverse the page (while cssSelector cannot).
Traversing the DOM in older browsers like IE8 does not work with cssSelector but is fine with XPath .
XPath can walk up the DOM (e.g. from child to parent), whereas cssSelector can only traverse down the DOM (e.g. from parent to child)
However not being able to traverse the DOM with cssSelector in older browsers isn’t necessarily a bad thing as it is more of an indicator that your page has poor design and could benefit from some helpful markup.
Ben Burton mentions you should use cssSelector because that’s how applications are built. This makes the tests easier to write, talk about, and have others help maintain.
Adam Goucher says to adopt a more hybrid approach – focusing first on IDs, then cssSelector , and leveraging XPath only when you need it (e.g. walking up the DOM) and that XPath will always be more powerful for advanced locators.
На XPath для 100% корректного поиска по классу вообще сложно выражение составить. https://stackoverflow.com/a/1604480/964478
Но бывает и наоборот, например, CSS селекторы вроде не умеют искать по тексту в теле элемента, или некоторые случаи с обращениями по иерархии.
Или, например, поиск по только ID (как в JS getElementById) по идее должен быть очень быстрым, они индексируются и не надо по всему DOM ходить.