Ну значит в твоём случае этот способ не годится. Попробуй узнать сколько свободной памяти есть и какого размера файл.
Почему? ![]()
А чё тут пробовать? ![]() Файл - 22gb. Free RAM - 2,6gb.
Файл - 22gb. Free RAM - 2,6gb.
Потому что отображение происходит на память, и физической памяти должно хватать для всего файла.
Файл - 22gb. Free RAM - 2,6gb.
Разве ты не видишь, что памяти не хватает? Текст ошибки тебе об этом и говорит.
Ну либо, если не для всего, то надо читать по частям, а это как раз то, от чего старались уйти.
Но читается и пишется-то оно и так быстро, даже без загрузки файла в память. Например, вот этот код:
public static bool AppendStream(Stream streamFrom, Stream streamTo)
{
long size = streamTo.Length;
byte[] buf = new byte[4096];
do
{
int bytesRead = streamFrom.Read(buf, 0, buf.Length);
if (bytesRead <= 0)
{
break;
}
streamTo.Write(buf, 0, bytesRead);
} while (true);
return streamTo.Length == size + streamFrom.Length;
}
нагружает винчестер почти максимально.
Медленно идет сама обработка данных, почему-то ![]()
Твоя логика примерно такая: если лампочка мигает медленно, значит нагрузки нет. Но возможно, что логика эта неправильная. Вдруг лампочка мигает только при записи. В этом случае логично, что на второй программе будет гореть, а на первой (читающей) будет редко мигать. Но при этом нагрузка при чтении никуда не денется.
я тогда не пойму, зачем
и
если файлы и так читаются и пишутся быстро? ![]()
Ну давай, докажи, что диски здесь не узкое место.
прикол ![]()
Вот код:
public static bool AppendStream(Stream streamFrom, Stream streamTo)
{
long size = streamTo.Length;
byte[] buf = new byte[4096];
do
{
int bytesRead = streamFrom.Read(buf, 0, buf.Length);
if (bytesRead <= 0)
{
break;
}
streamTo.Write(buf, 0, bytesRead);
} while (true);
return streamTo.Length == size + streamFrom.Length;
}Файлы читаются и пишутся быстро (так же, как при обычном копировании файлов в винде). Всё, доказано ![]()
доказано
Не доказано. Ты вообще понимаешь, что такое “доказательство”? Это в курсе математической логики изучают, там три части - теория алгоритмов, теория моделей и теория доказательств.
Конкретно в твоём примере ты утверждаешь, что файлы читаются и пишутся так же как при копировании (не медленнее). Из этого следует, что время, затрачиваемое на работу процессора над алгоритмами поиска пренебрежимо мало. Значит процессор не узкое место. И если ускорить чтение и запись, то общее время работы можно сократить (т.е. работу ускорить).
Я понял. Вы пытаетесь мне объяснить, что процессор выполняет обработку данных намного быстрее, чем они читаются с накопителя. Но в таком случае, накопитель всё-равно должен быть нагружен по максимуму. Почему этого не происходит? ![]()
накопитель всё-равно должен быть нагружен по максимуму
Да.
Почему этого не происходит?
Это происходит, но почему-то Вы считаете (думаете), что не происходит.
Могут быть, конечно, редкие случаи аппаратных неисправностей, но мы считаем, что у вас нормальная система (процессор не перегревается и не снижает частоту).
Это когда нет ничего, кроме чтения/записи?
А когда есть, то медленно?
Но чтение 22 ГБ с HDD всё равно ж много времени займет, с норм SSD будет быстрее.
А про поиск, профайлер может помочь понять что выполняется долго если это что-то типа случайных вызовов чего-то долгого (UI, …) или что-то внезапно занимает больше времени, чем предполагалось.
Тут не видно comparer, и непонятно что за diff и почему внутренний цикл не по размеру прочитанного буфера.
Но когда он действительно нагружен (например, кодом копирования из предыдущего поста) - то это видно. Он и тарахтит, и лампочка горит, и в диспетчере задач циферки скачут. А тут ничего! Всё тихо ![]() Еле-еле какая-то активность.
Еле-еле какая-то активность.
Как он может быть нагружен, если все индикаторы говорят об обратном? ![]()
Ну да. Если что-то ещё делать, то, естественно, скорость сразу падает. Но это, всё-равно, несравнимо быстрее, чем тут. Тут вообще почти нулевая активность.
comparer - делегат. В итоге вызывает это:
public static bool IsPatternAtPosition(this byte[] input, byte[] pattern, int position)
{
int max = pattern.Length;
int diff = input.Length - position;
if (diff < max) { return false; }
bool match = true;
for (int i = 0; i < max; ++i)
{
match &= input[i + position] == pattern[i];
if (!match) { return false; }
}
return true;
}diff это последняя позиция в буфере, после которой идти дальше нет смысла. Потому что patternLength превышает размер остатка.
Уже переименовал некоторые переменные.
Он глючит. А когда не глючит, я не понимаю, куда там смотреть. Хотя раньше пару раз юзал. Раньше, вроде, интерфейс понятнее был. Или кажется.
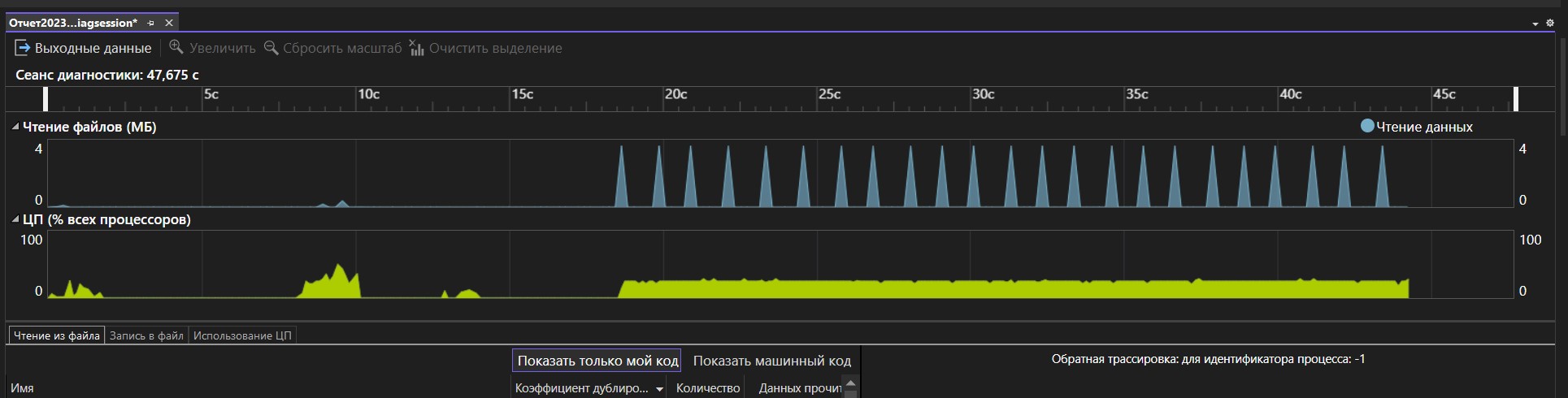
И что тут? Раньше был список методов и показано, какой сколько по времени выполняется. А сейчас внизу только список файлов, к которым обращается программа.
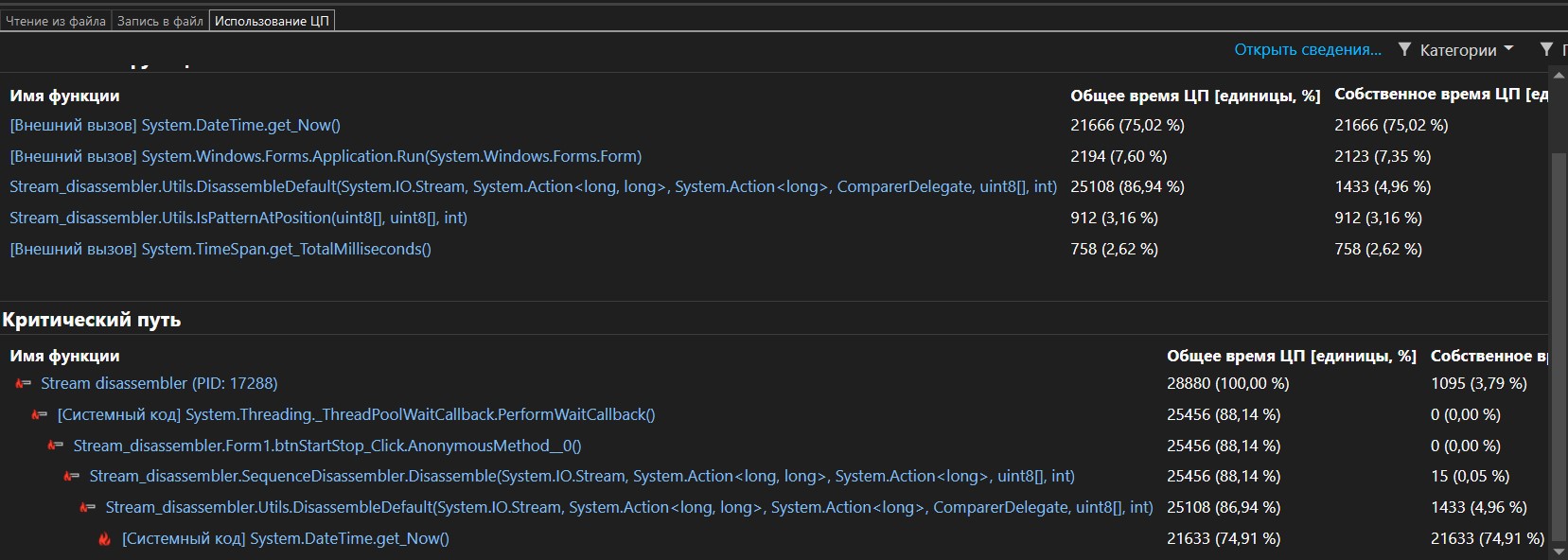
Похоже, что больше всего времени уходит на получение текущего времени. А накопитель тут не при чём, как и ожидалось. Ну или винда через накопитель время получает.
Это может быть и потому что оно показывает по функциям, а многое в том цикле – не функции.
Но да, оно вроде бы медленное, Environment.TickCount или хотя бы DateTime.UtcNow быстрее.
c# - Why are DateTime.Now DateTime.UtcNow so slow/expensive - Stack Overflow
DateTime.UtcNow and DateTime.Now performance improvements in .NET 6
1 лайк
Охренеть он теперь быстрый ![]() Даже никакие
Даже никакие Кнуты-Моррисы-Пратты не понадобились.
Жалко, что средства диагностики постоянно тупят. Помните же я писал, что профилировщик не запускается? Вот, а сейчас он решил начать запускаться. Я и не знал.