До 2018 года GUI Докера для винды и ПО для мышей/клавиатур Razer не запускались вместе потому что в них был один и тот же баг скопированный из ответа на StackOverflow
Обе программы пытались через глобальный мъютекс предотвратить запуск более одного экземпляра себя.
Для создания мъютекса нужно какое-нибудь уникальное (но воспроизводимое этой программой) значение.
Обе программы были на .NET и там у каждой программы есть GUID.
Они пытались программно получать этот GUID, но вместо него получали GUID библиотеки самого .NET.
Assembly.GetExecutingAssembly().GetType().GUID
вместо, например,
Assembly assembly = Assembly.GetExecutingAssembly();
var attribute = (GuidAttribute)assembly.GetCustomAttributes(typeof(GuidAttribute),true)[0];
var id = attribute.Value;
Я для такого обычно просто записывал в коде (литерал) какой-нибудь сгенерированный GUID. Тогда подобные баги невозможны
Интересно, зачем было так делать, есть ли какие-то преимущества у такого способа
Похоже что нужно. Этот феномен можно отнести к высказыванию лень двигатель прогресса. Так потихоньку и придем к микрофонной IDE.
Пробухтел в микрофон - не работает код. Оп-ля и отладчик провернул все что нужно.
Надиктовал - есть задание не знаю как начать. Оп-ля и IDE сваяла листинг.
Но и JSON тоже далеко не торт. Автор впихивал спецификацию на визитку, но не уточнил кучу деталей, и даже не версионировал его (типа это просто алфавит и не надо в него ничего добавлять). В итоге куча разных спецификаций (тоже не идеальных) и парсеров.
И в том числе там Юникод, с которым тоже всё сложно. http://replicated.cc/concepts/unicode — статья о том, что большая часть сложностей в Юникоде из-за мало кому нужных фич, мертвых языков и т.п.
The Pareto principle says 20% cost gives 80% value. Well. With Unicode, it is more like 99.999% of costs gives 0.001% of value. Or vice-versa.
…
Unicode belongs to the same family of interoperability standards as IP or HTTP or Ethernet. For such a standard to work, everyone in the world must be able to read and write it. Because that’s what it’s for! Such a standard must be 80/20 by design because it imposes costs on basically everyone. For every feature, we should ask whether it is worth imposing this cost on everybody in the world .
Exactly the same logic applies to any interoperability standard. A good standard is 80/20 and final.
Где-то глубоко в ядре винды есть функция, единственная задача которой — исправить имя какой-то Майкрософтовской Bluetooth мышки (удалить символ ®, который почему-то оказался там не в той кодировке).
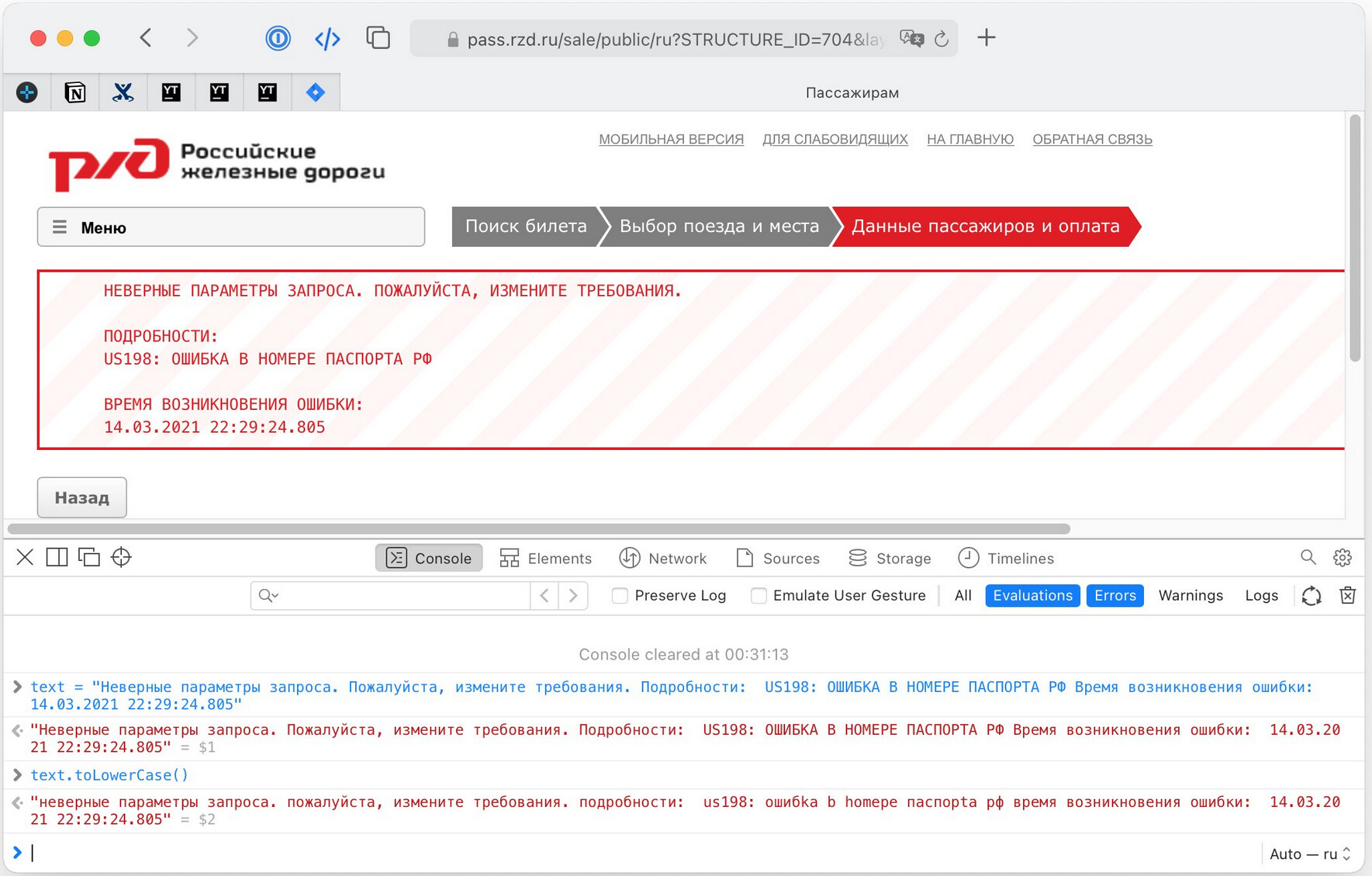
xxx: API РЖД тексты ошибок присылает капсом. При переводе в нижний регистр все возможные буквы оказываются латиницей.
yyy: в русскоязычных сообщениях об ошибках?)
xxx: Да, сообщения типа “ПО ЗАДАННЫМ ТРЕБОВАНИЯМ НЕТ СВОБОДНЫХ МЕСТ”. Делаешь lower case, получаешь
“по задаhhыm tpeбobahияm het cboбoдhыx mect”
yyy: o_O
xxx: Когда мы это нашли, то рабочий день тут же закончился, и мы всей командой пошли в бар.
Ладно бы еще если бы все буквы были латинские, тогда можно было бы объяснить отсутствием поддержки кириллицы где-то. Но тут же встречаются и кириллические буквы.
Разве что может быть сделали латиницу для тех букв, которые нормально в ней смотрятся (без Б —> 6, Я —> 9| и т.д.), чтоб хоть частично работало там, где не поддерживается кириллица.
Я специаально так делаю для регистрации в базе номеров авто приходящих на предприятие на погрузку. Все в капсе и одинаковые по написанию обязательно в латинице. А что бы искать потом без проблем по номеру, не взирая на то, как этот номер ввел бестолковый пользователь. Возможно и у них что-то там подобное, ну заодно через такой блок перекодировки и сообщения об ошибках прошли
Дык, буквы, которые в РФ сейчас допускаются в государственных регистрационных знаках (ГРЗ) , только такие и есть - только те, что имеют одинаковое написание в кириллице/латинице.
У нас тоже вроде так. Но можно ввести AE6040BB как латиницей, так и кириллицей, а можно и вперемешку. Кого и как угораздит, то и правильно с точки зрения пользователя. А еще изредка попадаются у древних грузовиков номера из прошлой жизни, с буквой Щ например )
Не понял. Так и вводит Щ. И Ц, и Б и прочее В латинице нет эквивалента, поэтому и проблем нет ) Он и А может ввести как кириллицей, так и латиницей. Это уже моя проблема потом правильно распознать номер в базе
Без разницы. Что при вводе для записи в базу, что при вводе для поиска в базе кириллица имеющая одинаковое написание с латиницей в капсе перекодируется в латиницу, не имеющая не перекодируется, и все в капс. Поэтому как бы он не ввел АА1111РР программе без разницы - в базе однозначное соответствие