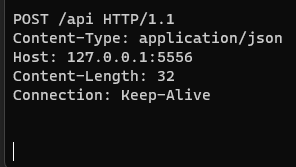
Во-вторых, надо проверить версию фреймворка на сервере, она может быть не такая же.
В третьих, надо прочитать про метод Receive
«( Если удаленный узел завершает Socket подключение к методу Shutdown и все доступные данные получены, Receive метод немедленно завершает работу и возвращает ноль байтов)»
я не вижу цикла, в котором Receive вызывается несколько раз до тех пор, пока он не вернёт ноль.
А как себя ведут другие серверы? Если принимают тело, то ошибка в коде этого сервера.
Кодировки имеют значение только если есть какой-то текст. А у меня тело не приходит. Каким местом кодировка может иметь к этому отношение? Она же применяется уже после того, как пришло тело (и если это тело - текст).
Но ок. Я сделал кодировки одинаковыми. Я просто забыл сделать это сразу. Потому что зачем что-то декодировать, если ничего нет, сами подумайте?
На сервере вот такая: .NET Framework 4.8.9181.0. Клиент и сервер я запускаю на одном и том же компе. Разве версии при этом могут быть разными? Я клиент и сервер в одном проекте скомпилировал.
Написал цикл:
private static byte[] Receive(Socket socket)
{
try
{
using (MemoryStream m = new MemoryStream())
{
while (true)
{
byte[] buf = new byte[4096];
int read = socket.Receive(buf, 0, buf.Length, SocketFlags.None);
if (read <= 0) { break; }
m.Write(buf, 0, read);
}
return m.ToArray();
}
}
catch (Exception ex)
{
System.Diagnostics.Debug.WriteLine(ex.Message);
return null;
}
}
Код ленивый, но для теста сойдёт.
На первой итерации он принимает 152 байта. И тело в этих байтах есть. Но тогда не понятно, чем это отличается от одиночного вызова метода .Receive() Могу опять ткнуть пальцем в небо и предположить, что пока генериуется цикл, проходит несколько миллисекунд за которые клиент успевает отправить тело до чтения данных сервером. Ну а почему ещё-то? Объясните мне это.
А на второй итерации сервер надолго задумывается над строчкой int read = socket.Receive(buf, 0, buf.Length, SocketFlags.None);, а потом read становится равно 0. Над чем он там думает полминуты - не понятно. Но так, явно, не должно быть.
А у меня нет других HTTP-серверов, кроме этого и того, что на питоне. Питоновский ведёт себя так же, но цикл я там не писал.
Точнее, есть ещё один сервер на C#. Но там только GET реализован. Другие запросы там пока не нужны. Но я уверен, что там было бы так же. Код ведь тот же самый.
Изменил код сервера (добавил задержку перед чтением данных):
Socket client = server.Accept();
Thread.Sleep(100);
byte[] buffer = new byte[4096];
client.Receive(buffer, 0, buffer.Length, SocketFlags.None);
if (buffer.Length == 0)
{
Console.WriteLine($"Zero bytes received from {client.RemoteEndPoint}");
client.Close();
continue;
}
string msg = Encoding.Default.GetString(buffer, 0, buffer.Length);
Console.WriteLine(msg);
Теперь с приходом тела проблем нет.
Как вы это объясните? Что про это говорит спецификация протокола?
Как можно избавиться от этой задержки? Так ведь не может быть, чтобы таким костыльным способом решалось.
Очень странно, но задержка в одну миллисекунду тоже работает
Где-то я уже такое видел Кажется, на канале one lone coderа. Он там сервер для игры на C++ писал и у него тоже что-то не работало (не помню что). Он добавил куда-то (не помню) задержку в 1 миллисекунду и заработало.
Очень странная фигня.
После такого надо святой водицы испить и берёзку обнять.
Как вы это объясните? Что про это говорит спецификация протокола?
Не знаю, читать надо. Но думаю, что сначала не про протокол, а про реализацию стека в операционной системе.
Мы же видели, что IP пакет по проводу идёт один, или не видели? Вопрос - что такое с ним делает ОС, если часть остаётся в буфере.
То есть, получается, нельзя просто так прочитать тупо всё сообщение целиком? Код зависает. Надо обязательно знать его размер. Чёт я на это никогда не натыкался. Сейчас пытаюсь вспомнить и получается, что я никогда не пытался вычитать всё сообщение от клиента. Я всегда читал только первые 1024 или 4096 байт. И длинные сообщения серверу не отправлял.
Код, который внутри Receive, не обязан понимать протокол HTTP, это твоя задача. Поэтому он и не определяет, сколько данных тебе вернуть, возвращает, сколько хочет.
Логику программы надо писать так, как будто бы байты приходят поштучно. Пришел новый HTTP-заголовок целиком - обработали. В зависимости от его содержимого последующие действия разные.
«Место окончания HTTP заголовков определяется пустой строкой, состоящей из двух последовательных символов перевода строки (CRLF - Carriage Return Line Feed), обозначаемых как \r\n\r\n. Это означает, что после последнего заголовка следует пустая строка, после которой начинается тело HTTP запроса или ответа.»
Но идею использовать класс HttpListener, в котором это уже всё закодировано, считаю более правильной.
Да это понятно. Просто вы написали “приходит новый заголовок”. Сразу возникает два вопроса: почему один? и разве они не только в начале приходят?. И третий: про какой заголовок тогда речь?.
А насчёт \r\n\r\n. Получается, что если длина заголовков нигде не определена, надо заранее выделять большой буфер. А потом, если тело есть, отделить его от заголовков и скопировать в какой-нибудь стрим (который надо тоже создать заранее). А ведь тела может и не быть. Тогда получится, что стрим (или буфер) для тела был создан зря и его нужно удалить.
Если это и правда так, я считаю это жёсткой недоработкой протокола. Во-первых, это банально не удобно в плане кодинга. Во-вторых: это было придумано в 70-х, когда все ресурсы были сильно ограничены. Не проще ли было в самом начале посылать два байта с указанием длинны до этих \r\n\r\n? Два лишних байта не повесили бы сеть
Но это я просто ворчу.
Возможно его не сразу прикрутили?
Llama3: «Возможность добавлять бинарное тело в POST-запросе в протоколе HTTP появилась с выпуском HTTP/1.1 в 1997 году. в спецификации HTTP/1.1, опубликованной в 1997 году (RFC 2068), появился новый заголовок “Content-Type”, который позволяет указать тип содержимого тела запроса, включая бинарные данные. Это позволило отправлять бинарные данные в теле POST-запроса.
В предыдущей версии HTTP/1.0 (RFC 1945) такого заголовка не было, и отправка бинарных данных в теле запроса не поддерживалась.
Однако, стоит отметить, что на практике отправка бинарных данных в теле POST-запроса была возможна и до выпуска HTTP/1.1, но это было нестандартное и не всегда поддерживалось всеми серверами и клиентами.»
Хотя это странно, в HTTP 1.0 наверное можно POST делать с данными.
«Some older HTTP applications do not recognize media type parameters. HTTP/1.0 applications should only use media type parameters when they are necessary to define the content of a message.»