здравствуйте!написал достаточно большой код для того что бы помощью 1 класса можно было сохранять и читать словари из текстового файла, этакий ПЗУ ,поскольку готового не нашел, вот сам код моего класса :
class dataBase :
def __init__ (self,base_name):
self.base_name=str(base_name)
def read (self):
base = open(str(self.base_name), 'r')
base_r = base.read()
st1 = ''
dict_r = ''
dict_r = {}
trash = 0
for i in base_r:
# print ('i:',i)
if i == ' ' or i == '\n':
continue
if not trash:
if not i == ':':
st1 += i
else:
trash = 1
else:
dict_r[st1] = i
st1 = ''
trash = 0
print('resulr READING - ', dict_r)
print ('base_name - ',str(self.base_name))
global stick
if str(self.base_name) == "dataSti.txt" :
print ('obnov stick!!!!!')
stick = dict_r
base.close()
return dict_r
def write (self,id,val):
self.id = id
self.val=val
print('write id - ',self.id)
print('write val - ', self.val,type(self.val))
data1 = dataBase (str(self.base_name))
base_r = data1.read ()
if str(self.id) in base_r:
# изменяем имеюoийся айди
base = open(str(self.base_name), 'r')
base_r = base.read()
base.close
#print('change')
tc = ''
dict_r = ''
trash=0
for i in base_r:
if trash == 0 :
if i == ' 'or i == '\n':
continue
if not i == ':':
tc+=i
else :
trash = 1
continue
else :
if i == ' ' or i == '\n':
continue
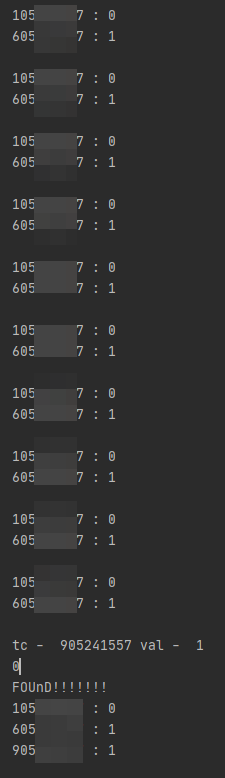
print ('tc - ',tc ,'val - ',str(self.val))
if str(tc) == str(self.id):
dict_r += tc + ' : ' + str(self.val) + '\n'
trash = 0
tc = ''
print (i)
print ('FOUnD!!!!!!!')
else :
dict_r += tc + ' : ' + i +'\n'
trash = 0
tc = ''
print ('OLD!!!')
print (dict_r)
base = open(str(self.base_name), 'w')
base.write(base_r)
del (base_r)
base.close()
else:
# добаляем айди
base = open('dataSti.txt', 'a+')
base_r = base.read()
newT = base_r + '\n' +str(id) + ' : ' + str(val)
base.write(newT)
base.close()
собственно тут все сложно, поэтому обьясню .метод read() рабочий и его мы не трогаем ,а метод write ,должен добавлять или же изменять пуyкты словаря (id эт то ,что до : ,а val это то, что позже) первым if он поверяет есть ли в файле пункт id и если нет - успешно добавляет новый, но если есть - он читает файл в for по одному символу перезаписывает все пункты ,но если пункт совпадает с нашим пунктом (id)то меняет в строках
if str(tc) == str(self.id):
dict_r += tc + ' : ' + str(self.val) + '\n'
trash = 0
tc = ''
print (i)
print ('FOUnD!!!!!!!')
меняет значение( то что после : ) на val и если выводить в консоль - мы видим следующее:
зачение удачно записывается,но как только начинается запись в сам файл следующего пункта - значение меняется на прошлое (в данном случае айди это пункт начинающийся с 905), а если он был последним - тоже самое ,каждая строчка это 1 проход по символу файла , а после пробела запись новoго блока из base_r
прошу прощение за смазывание