Вааааабще не в тему, но я не удержусь.
Меня интересует тема оптимизации высокоуровневого кода. Т.е. сколько стоят условные операции в тактах - мне примерно все равно (мол от них я никак не избавлюсь, увы. это есть в коде. должно быть так и никак иначе. единственное, что я могу - принудительно векторизовать = привет, интринсики).
А вот что-нить более полезное/интересное я бы с удовольствием почитал.
Неважно в каком виде.
Просто все что я смог найти это набор самых банальных клише.
Типа запустим профайлер, увидим хотспот, подумаем об алгоритмической сложности, навалим интринсиков, бахнем многопоточку. Профит.
Я б тоже не против не банальное найти, но в целом искать узкие места в профайлере и думать как улучшить вполне работающая универсальная схема для всех платформ и уровней )
Еще дополнительно к этому, или даже вместо если нет времени/денег на зп, можно тупо более мощный сервер купить если это серверное ПО (если не серверное, то попытаться перенести вычисления туда).
Оптимизациями-то вообще уже мало кто сильно занимается, во многих случаях у бизнеса есть куча более важных задач
Ну, если не профайлер, наверное, в сторону ФП, точнее, отказа от императивного подхода. Динамическое программирование и прочая матчасть. И алгоритмическая сложность - штука не банальная.
Вот есть у меня задача. Профайлер говорит, что 70% уходит на функцию. Ее я ускорить никак не могу. Потому что там берутся произвольные значения из двумерного массива, делятся, умножаются и прочее.
Основная проблема в том, что значения произвольные. И большая часть уходит на кеш-мисы. И все. Больше я ничего сделать не могу. Конец.
Ускорить оставшиеся 30% - уже не так серьезно. Так что… Грустно
Несильно как-то и согласен.
Закон Мура не работает. И в моем мире все больше сил должны уделяться на оптимизацию.
И все больше вещей хочется видеть в realtime, причем на устройствах пользователей. Те же маски/фильтры/прочее в prisma, vk, tiktok
Не понял от слова совсем. Императивный код я могу дергать как только захочу.
Просто пример из жизни.
Было нечто подобное
for(int i = 0; i < size; i++) {
arr[i] = (some_magic_const + another_magic_const * i) / magic_const_again;
}
С условным императивным - я могу переписать это как
И поскольку это нигде не векторизуется, то пишутся интринсики. Все. Красиво(условно) и быстро. Никакая функциональщина в текущих реалиях этого не может. Поэтому не - пасиба. Неинтересно.
Оптимизация возможна для частных случаев. Для примера, если у вас есть сортировка за O(N) то быстрее Вы уже не сделаете.
Поэтому вот так вот абстрактно спрашивать нет смысла. Ответы будут такими же абстрактными.
Так у вас тут 3 константы.
(A+Bi)/C
Можно упростить A/C+B/Ci
D+F*i
Было 3 операции стало 2.
А затем умножение заменить сложением. Останется одна операция.
for(int i = 1; i < size; i++) {
pref+=F;
arr[i]=F;
}
Затем развернуть цикл.
Основная проблема в том, что значения произвольные. И большая часть уходит на кеш-мисы. И все. Больше я ничего сделать не могу. Конец.
Так закешируйте так что-бы промохов было мало. Не важно какая функция была бы НС или вероятностные деревья решений могут найти эту случайную функцию с аккуратностью в 10%. Покроете большинство случайных данных.
Дело не в этом. А в том, что надо смотреть фунциональную зависимость каждой переменной. Т.е. строить граф. А потом над ним заниматься оптимизациями.
Не совсем так. Это верно только для сортировки как вещи в себе. Если же рассматривать ее в контексте других алгоритмов, то очевидно, что можно получить и задействовать элементы в нужном порядке гораздо быстрее за счет распараллеливания.
Точность. Падает точность. А она критична. Умножать нельзя. Сразу поделить тоже.
Ну-ка. Вот есть у меня аффинное преобразование. Где dst[x,y] = src[x’,y]. Где x’ = xa1 + yb1 + c1, y’ = xa2 + yb2 + c2. Как же мне убрать кешмисы? Т.е. итерации идут по x,y. Получаю я тьму проблем с кешмисами. Даже если я убираю умножение. Даже если я работаю с целыми. Это несильно сказывается на скорости. Потому что основная проблема все та же - кешмисы. И как мне эт закешировать?
Можно сразу. Только надо разбить на промежутки 2^n-2^k длина промежутка определяется количеству нулевых битов F:=another_magic_const / magic_const_again. C:=F and (F-1)
В внутри промежутков падений не будет. Между промежутками добавлять +1.
В каких случаях добавлять +1 можно вычитать в описание алгоритма замены деления на умножения изложенного у Агнера.
Integer division by a constant (all processors)
Надеюсь вы уже пробовали. При заполнение новой картинки перебор следует делать по новым координатам x’, y’ вычисляя старые. Вычисления происходят только на границе, а между ними идёт интерполяционное заполнение.
Аффинное вращение можно представить как три последовательных скоса. https://dxdy.ru/post1092608.html#p1092608
Скосы опять таки делать блоками. Блочное преобразование делаем через инстрики.
Нет. Не следует.
Итерирование по dst обусловлено правильным заполнением оффсета. (аля border_mode in OpenCV).
Пойдем по новым координатам - сделать адекватно так уже не сможем.
Что значит интерполяционное заполнение? Представим, что у нас нет поворота и сдвига. Только scale. Где условный пиксель src должен перейти сразу в некое множество пикселей на дст. Вы это называете интерполяционным заполнением?
Что такое dy,dx? И зачем тут транспоринрование. Да еще и блочное?
А сейчас о чем речь?
Отдельно (зачем?) выделяется вращение. Именно вращение? Или вы про rst разложение самого преобразования?
Для Аффинных сможем для перспективных с потерью точности.
Если делать прямой алгориитм то умножение матрицы это 27 умножений чисел. А интерполяция это применение формулы a*(1-t)+b*t всего 2 умножения.
Плюс мы должны проверить попал ли точка в нашу картинку или вышла за границы.
Есть такое правило для оптимизации вынос условия из цикла.
for i:=0 to 10 do
if i<5 then x:=x+1 else x:=x-1;
if (x<5) then for i:=0 to 5 do x:=x+1
else for i:=5 to 10 do x:=x-1
Второй код будет работать значительно быстрее.
Если вы начнёте размышлять о такой оптимизации, то от прямого алгоритма вы перейдете к алгоритму scanline. Который как раз делает обратное преобразование.
Так оптимизация возможна только для частных случаев. Вы рассматриваете все частные случае и получаете общее решение.
Это более общий метод чем просто скопировать повторив пиксели. По скорости они не сильно отличаются. Хотя для масштабирования Вам прямой метод будет проще дальше оптимизировать. Распределить цикл(развернуть цикл).
Вы спрашивали про кэш. Блочное работает быстрее. Это был ход мысли. А практические такое и для маштабирования и для поворота даст выигрыш в скорости за счёт снижения кэш промахов. Можете почитать спецификацию на Вулкан 1.0 там идея растеризация та же самая выделить фрагменты 16 на 16 пикселей для того что-бы они хорошо ложились на кэш видеокарты.
Что такое dx,dy? Наклон повернутой картинки. Вы же знаете, что прямое умножение 2-х матриц работает медленнее, чем если транспонировать умножить и потом снова транспонировать? И тут дело не в кэше, вернее не совсем в кэше. А в блоке предварительной выборке(это подсистема кэша). Который может предсказать линейную загрузку и не может предсказать рендомную.
for x=0 to 10000 do
for y:=0 to 10000 do
a[y][x]:=a[y][x]*2;
for y=0 to 10000 do
for x:=0 to 10000 do
a[y][x]:=a[y][x]*2;
Первый код будет медленнее чем второй. Из за проблем с кэшем. Если во втором коде мы линейно(последоватлеьно) обращаемся, к памяти, то в первом это будет через равные промежутки, что для компьютера выглядит как случайная выборка. И он не может быстро загружать данные из памяти в регистры. Хотя сейчас в технике в этом плане сделал большой прорыв, так что не факт.
Нет. RST применяется в обратной кинематики для ускорения расчётов. В данном случае он не помощник.
Это просто мысли в слух. Так как такое разложение потребует 3-х операций чтения и записи, то оно проиграет scaline по скорости работы с кэшем. Хотя кодировать его проще.
Что это такое?
Знаю scanline, как наложение отрезков на прямую и взаимодействие с ними.
Но вы, видимо, про найти [a,b], фиксируя одну из координат, где точка попадает в dst.
Если так - то да. Это понятно. Ускоряет.
Но не решает проблему с кешмисами. Что влияет в разы сильнее.
В данном случае не интересует. Мне интересен исключительно общий вариант. Где есть src, dst, (Inversed)AffineMatrix. Разбивать это на подслучаи R or S or T не хочется от слова совсем. Только если разбивать в любом случае.
Слишком архитектурно-специфично. Не интересует.
Кстати, не уверен.
Т.е. перейти от dst[x,y] = src[x’, y’], x’ = a1x + b1y + c1, y’ = a2x + b2y + c2 к dst[x’,y’] = src[x,y] мешают два момента.
BorderMode. На текущий момент можно представить, что доля оффсета достаточно невелика. Скажем процентов 30. И для этого останется оригинальное заполнение с итерированием по dst.
scaling. И вот тут не совсем понятно. Т.е. когда есть не просто поворот/перенос. И как это сделать это “суммарно” непонятно. А вот если разбить это на rst. То становится вроде бы значительно проще.
А зачем тут умножение матриц? Меня не интересует вычисление координат. Мне нужно именно скопировать значения из src в dst.
Но вы, видимо, про найти [a,b], фиксируя одну из координат, где точка попадает в dst.
Если так - то да. Это понятно. Ускоряет.
Тут я Вас не понял.
Но не решает проблему с кешмисами. Что влияет в разы сильнее.
Да не решает. Так мы только перешли к однородной операции к простому циклу.
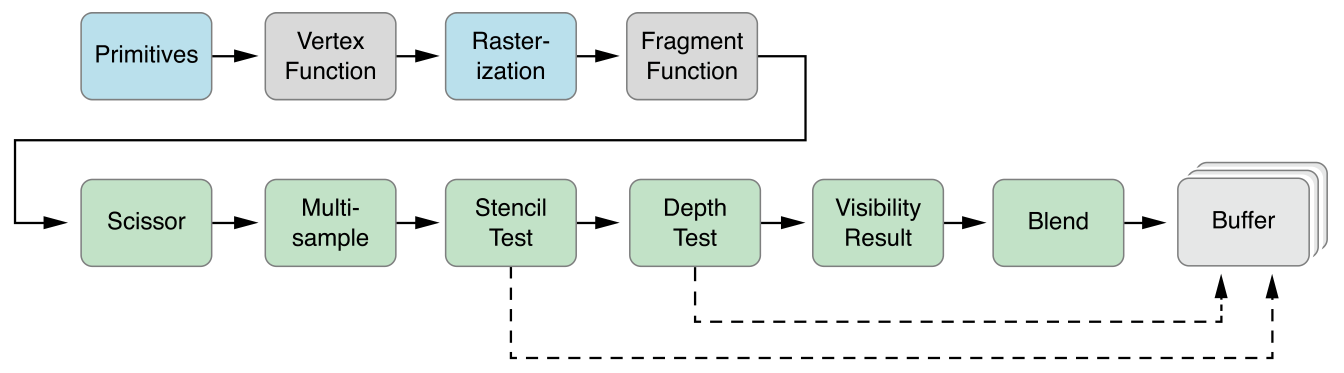
Вы не поняли. В вулкане этап растеризации делается программно в отличие от DX, OGL. Тут нет архитектурной-специфичности. Вернее даже растеризацию делает не сам вулкан, а он уже принимает растеризоване примитивы.
Конвейр рендеринга
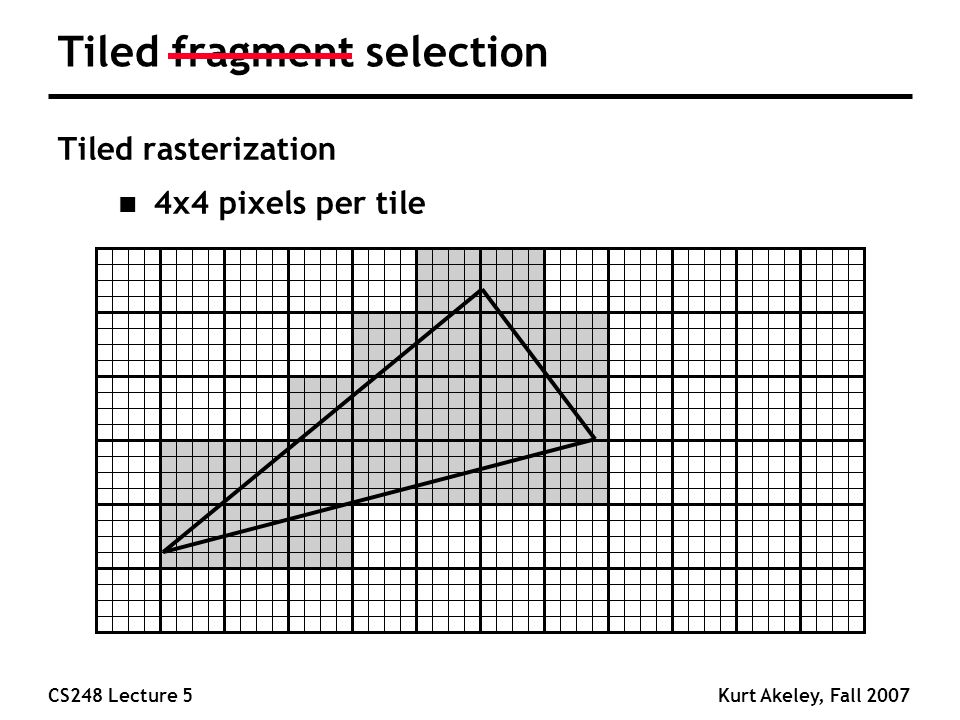
Так вот чтобы снизить число кэш промахов вам нужно разбить вашу картинку на фрагменты в виде плитке 16х16 или 32х32 пикселя. Для примера на картинке плитка 4х4
Как это поможет?
Еще раз.
У меня есть примерно такой код
for(int y = 0; y < height; y++) {
for(int x = 0; x < width; x++) {
int32_t x_coord = a1 * x + b1 * y + c1;
int32_t y_coord = a2 * x + b2 * y + c2;
if (x_coord >= 0 && x_coord < src_width && same_with_y_coord)
dst[y * width + x] = src[y_coord + src_width + x_coord];
}
}
Окей. Разбили цикл варианты при попадании x_coord и y_coord в нужные промежутки.
Не решает проблему с кэшмисами.
Ваш вариант с разбиением на квадраты в 32x32/16x16. Как это поможет?
Проблемы с кешом в такой записи с dst нет. Она есть в src. Ваш вариант ее не решает.
Мне не нужно отрисовывать. Мне нужно вычислять координаты. Мне нужно просто выполнить аффинное преобразование, закинув в dst “нужные пиксели” src. Конец
Update.
Пардон, дошел вариант с блоками. В теории да. Должен спидапнуть. Прикольно. Надо будет тестануть. Спасибо
Кэш устроен сложнее чем нам кажется. Это решето с очередью в 4 элемента. Советую ознакомиться с его устройством.
Дэвид М. Хэррис, Сара Л. Хэррис Цифровая схемотехника и архитектура компьютера