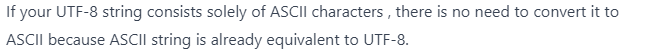Дело не в выводе. Мне надо, чтобы коды символов в строке совпадали с их кодами из таблицы ASCII. Это для OpenGL. Иначе он текстурный шрифт неправильно выводит. Я просто до этого с русскими буквами в линуксе ни разу не тестил. Думал - какая разница-то. Не знал, что в линуксе UTF-8.
Ну или в ANSI там, или ещё во что-то. Однобайтовые символы это же ANSI, вроде
По заявлению автора, это должно преобразовать UTF-8 в wstring. Но оно, почему-то, из русского “абвг” делает “abvg” Это странно как-то.
Это я в линуксе запускаю. В винде и без этого работает.
Ещё вот такое нашёл:
Если правильно понял - если строка UTF-8 содержит только символы из таблицы ASCII, то коды символов идентичны.
Но это, наверное, про старую версию ASCII, где русских букв ещё не было
Если надо во что-то конвертировать, то в не-юникодную кодировку, видимо CP1251.
Но звучит странновато, что OpenGL не может справиться с юникодом. Может дело в том коде?
Пытался скомпилировать проект на старом ноутбуке с реальным линуксом (а не в виртуальной машине). Это тоже была длинная и смешная история. Но в результате всё получилось, всё работает.
По ходу дела посмотрел на код свежим взглядом и обнаружилось, что у меня файлы исходников, каким-то чудом, оказались в кодировке UTF-8. Как так получилось - я вообще без понятия Это значит, что все символы с кодами 128-255 (тут могу ошибаться) кодируются тремя байтами.
Перекодировал их обратно в однобайтовую ANSI и всё заработало. Не нужны никакие программные перекодировки, iconv и прочее
Я этот код ещё никуда не заливал.
Я код пишу в вижуалке с учётом приколов компилятора GCC. То есть, чтобы оно и там и там компилилось. Например, в вижуалке чтобы получить доступ к костанте M_PI надо сделать так:
#define _USE_MATH_DEFINES
#include <iostream>
А на GCC нужно просто заинклюдить <cmath>. По-этому, использую вот такую констукцию:
Скорее всего, на других компиляторах и на маке это работать не будет. Но мне оно и не надо.
Сегодня выяснил такую штуку:
Пишем код в вижуалке и копируем его в линукс. Если в коде уже были русские буквы, то всё компилируется и работает. Если русских букв не было и если начать редактировать код в линуксе, добавить русские буквы и сохранить, то сохраняется оно по-умолчанию в UTF-8 (скорее всего, это от редактора зависит). А если в коде до копирования уже были русские буквы и файл был в ANSI, то при редактировании в линуксе он так и оставляет его в ANSI.
Но я не помню, чтобы я редактировал код в линуксе и добавлял русские буквы. Я копировал файлы кода уже с русскими буквами. Получается, что файлы уже были в UTF-8 в винде. Видимо, это произошло когда я экспериментировал с юникодовыми именами файлов. Я напрямую в код вставлял юникодовый символ. Видимо, в тот момент вижуалка их конвертнула.
Прикол в том, что на винде компилятор вижуалки и GCC понимают код в формате UTF-8 и нормально с ним работают. По-этому, я и не замечал разницы.
А в линуксе, как оказалось, - нет. Там только однобайтовая кодировка нужна. ЭТО ПОДСТАВА, КАРЛ! КАРЛИК!
Может и так. Но я имел ввиду, что для вывода текстурного шрифта в OpenGL ему нужна однобайтовая кодировка (если не использовать библиотеки). Без библиотек UTF-8 (и другие кодировки) он не понимает. Он каждый байт обрабатывает как отдельный символ таблицы ASCII с соответствующим кодом.
Но это в линуксе. На винде это прекрасно работает и с UTF-8. Теперь, зная это, я не совсем понимаю, почему это так Почему передаваемая в OpenGL двухбайтовая UTF-8 русская буква в винде сама превращается в однобайтовую из ASCII
Суждение: «передаваемая в OpenGL двухбайтовая UTF-8 русская буква в винде сама превращается в однобайтовую из ASCII». Было ли оно сформировано по законам логики или вопреки им?
Ну там сначала грузишь текстуру со шрифтом, потом разбиваешь её на 256 квадратиков. Так, чтобы порядковый номер (ID) каждого квадратика соответствовал коду символа в таблице ASCII. Потом генерируешь из них экранные списки (display lists). Это не обязательно. Всё зависит от того, как хочешь реализовать вывод текста. Но там суть всегда одна - передать в функцию код символа из ASCII. Если всё-таки пошёл по пути экранных списков (и не используешь библиотеки) и каждый символ на текстуре расположен в правильном месте, то текст выводится так:
Всю эту кучу действий я лаконично объединил в одну простую фразу: «передаваемая в OpenGL двухбайтовая UTF-8 русская буква в винде сама превращается в однобайтовую из ASCII».
Потому что:
Русская буква в кодировке UTF-8 занимает два байта? - Да!
Функция вывода текста OpenGL хочет, чтобы эта буква занимала один байт? - Да!
Но я же передаю в неё двухбайтовую букву? - Да!
Но при этом, на винде оно работает правильно? - Да!
То есть, буква из двухбайтовой сама как-то превращается в однобайтовую? - Да!
Везде Да.
Тогда не понимаю, что вас смущает? Всё по законам логики, вроде
Но может это я опять чего-то не понял.