Здравствуйте!
Подскажите пожалуйста, кто знает. Как можно распарсить файл? Ну, то есть, мне нужна последовательность бит, даже не байт. Например, я хочу сделать алгоритм, который выводит в консоль последовательно побитово файл. Сам создал файл, текстовый например, и вывел его содержимое в консоль побитово. Или видеофайл. Я хочу для поднятия навыка программирования сделать собственную программу копирования побитово любого файла. Вот такую поставил себе задачу)
Так и где тут парсинг?) Это просто чтение.
Но читать всё равно только байты можно, так что надо их конвертировать в биты потом. Либо BitSet, либо сдвиги, можно еще свой стрим как тут или тут.
1 лайк
Наверное не то слово подобрал - “парсинг”)
В общем да, надо разложить содержимое на биты. А потом побитово выводить в консоль. Спасибо за ссылки, буду изучать.
Предварительно ознакомился. Оказывается нет средств, которые ориентированный на побитовое чтение файла. Можно только сначала вынуть байтами, а потом самому разложить на биты.
Пока понял так.
Подскажите пожалуйста направление.
Я понял, что не обязательно пользоваться битами, можно байтами.
Но мне для копирования надо увидеть байт “сверху”
Инпут стрим читает из чего-то, а мне надо не читать, а просто разбирать сверху. Копировать.
Например, не буду же я осуществлять копирование видеофайла воспроизведением видео.
Как “брать” файл для разбора целиком, чтобы потом его собрать без повреждений. Такая задача. Я понимаю, что это типа изобретения велосипеда. Программа копирования вшита в операционку))) Но я хочу созданием своей такой программы повысить навык. Т.е. это практика для повышения скила.
Я сохранил весь файл в массив байтов. Потом решил вывести в консоль первые 100. Но получилась какая-то ерунда. Почему-то это не 8-битные группы из нолей и единиц.
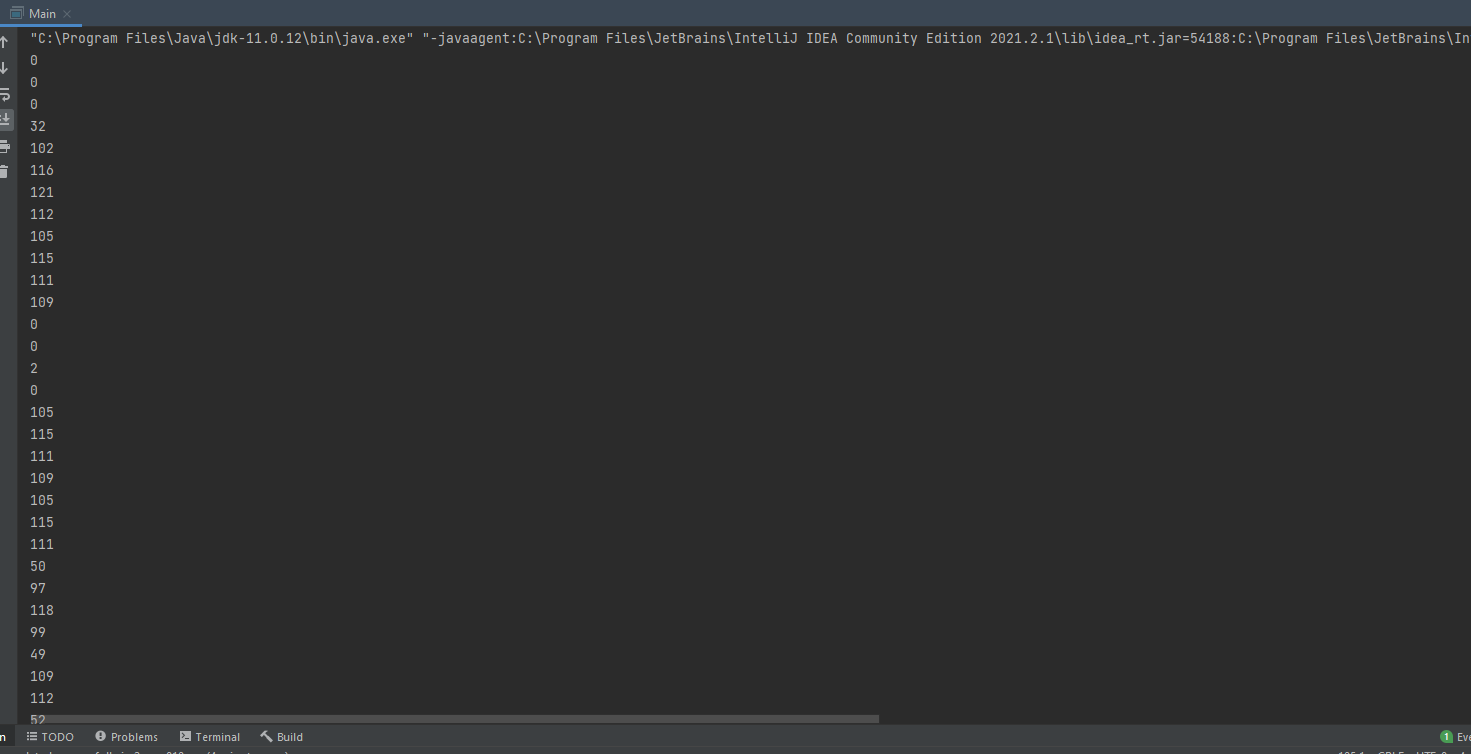
Это как? 
Так оно просто в виде числа выводит, откуда оно знает как вам надо.
102 это ж 01100110 например. Или например 66 в шестнадцатеричной системе, бывает она удобнее при работе с байтами.
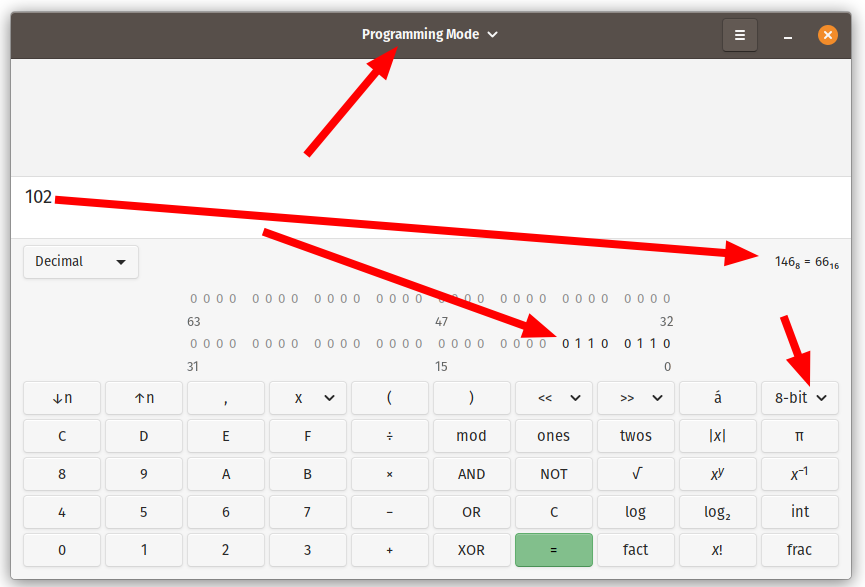
Чтоб в виде битов, надо достать их и выводить.
Ясно, буду изучать возможности BitSet. Спасибо.
Скажите, я правильно понимаю, что число 102 мне показывает идея потому, что так выгоднее представлять это число для памяти? Т.е. 102 - это три байта, а 01100110 - это 8 байт?
Причем тут память? Это вывод строк в консоль. В памяти числа хранятся не в виде строк.
А выгодно это потому что в 99.9% случаев люди ожидают увидеть число в десятичной системе счисления )
byte это такой же числовой тип как int и т.п., просто меньше размер.
16 если строка хранится в UTF-16, но Джава может это оптимизировать (с 9 Джавы вроде по умолчанию).
What is the Java's internal represention for String? Modified UTF-8? UTF-16? - Stack Overflow
Ясно. Пока продолжаю только ознакамливаться с темой. Но по первому взгляду, нигде не нашел стандартных средств и методов, для вывода-распечатки байтов файла в двоичном виде… Странно. Это если кто-то желает увидеть содержимое файла в двоичном виде, должен всегда придумывать свой класс для таких дел?..
то они откроют его любым хекс редактором )
Там впрочем обычно в 16 сс по умолчанию. Но вывод в 10, 8 и 2 обычно тоже есть.
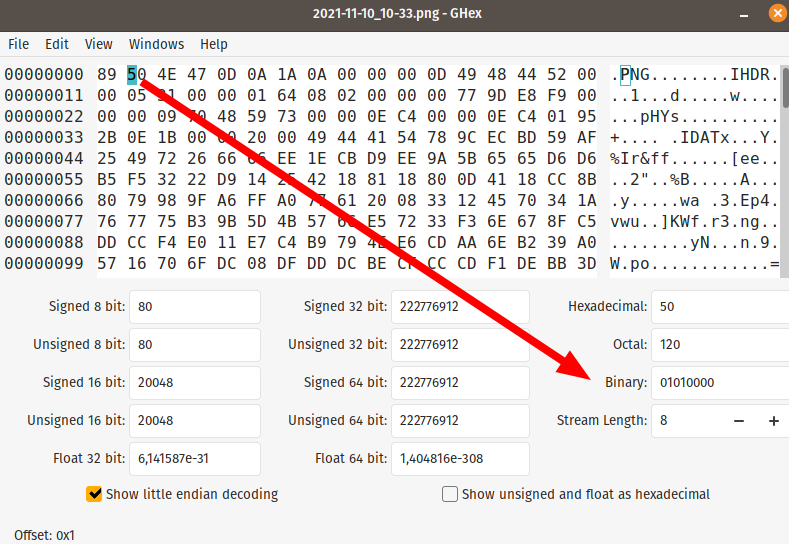
Нет, я имею ввиду тех, кто желает что-то автоматизировать в действиях с битами байтов файла.
Т.е. программного средства в виде классов для работы такой нет. Типа toString(), только toBit() )))
Так вот же
Еще в toString вторым параметром можно любую сс передать.
Это что? вторая сс… Я пока не понимаю
Спасибо. сс - система счисления)
Скажите пожалуйста, а есть такой вид потока, который выводит содержимое файла так сказать по одному байту? Ну, типа как в цикле, чтобы в каждой итерации, я мог что-то с байтом делать и отправлять его обратно в поток…
Спасибо большое. Пользовался стримами не раз, а этого не знал)